Home The APU: Novel Hardware for Accelerated Similarity Search
Author: George Williams
In this blog, we will describe our custom APU chip—an innovative and exciting new design that will accelerate similarity search for a broad range of applications.
But, before we get into the details of our chip, let’s take a step back and first talk about similarity search and how it is used today.
Similarity search is different than traditional database search. Objects in a similarity search database are represented numerically either as a vector of floating point numbers, integers, or as a bits.
These numeric representations are sometimes known by other names, such as “embeddings”, “codes”, or “fingerprints.”

Molecule fingerprints as bit-vectors. Each bit represents the presence of a specific functional group.
In similarity search, a query is performed against this numeric database by computing a “distance” between the query and the objects in the database. Objects that are closer to the query are ranked higher in the results.
Usually an application may only care about getting a few of the top results from a similarity search. These top results are called the “nearest neighbors.” The application will typically only need “K” of them, or it may need just the neighbors that fall within a distance threshold. The value of “K” or the threshold are search parameters for Nearest Neighbor Search (NNS).
Similarity search is integral to several application domains, such as computational drug discovery and visual search. In computational drug discovery, similarity search can be used to search large molecule databases for potentially beneficial biopharmaceutical drugs. These molecules can eventually turn into “seeds” for actual synthesis and clinical trials.
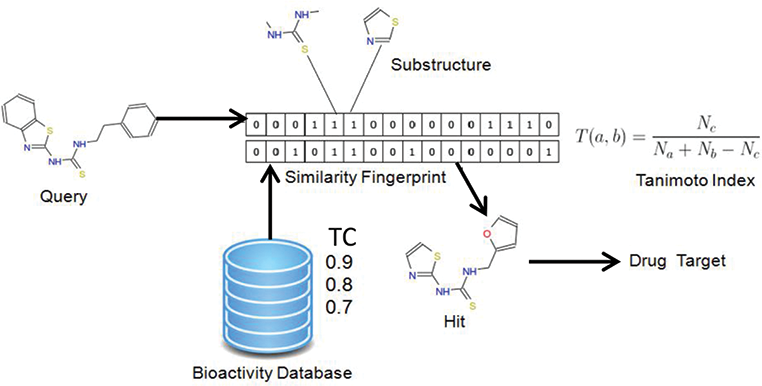
Similarity search is useful in computational drug discovery.
Visual search is a popular application in e-commerce that leverages similarity search. Here, users take a picture of something they like with a mobile app and are then instantly matched with visually similar products in inventory. There are several great visual search apps from companies like eBay, Google, Amazon, Microsoft, Pinterest, Clarifai, Walmart Labs, Wayfair, and many others.
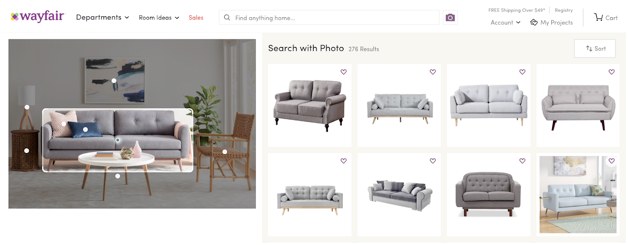
An example of Wayfair’s visual search application. Searching for the right couch has never been easier!
Similarity search databases can be very large. For example, there are several openly available molecule databases that contain tens of millions of molecules. On the e-commerce side, it’s now commonplace to encounter product inventories that number into the billions of items.
End users of similarity search applications, whether they are shoppers or cheminformaticians, want their search results as fast as possible. Unfortunately, performing a distance computation between a query and all the objects in a database can be slow, especially as the database gets larger and larger.
Scaling similarity search often involves employing a few different tricks. Briefly, they can be categorized as follows:
These tricks are often combined — such as in our custom chip for similarity search, called the APU.
We introduce the APU, the Associative Processing Unit, for hardware accelerated similarity search. The APU chip is composed of multiple banks of SRAM memory cells interleaved with computational bit-logic.
Let’s have a closer look at how similarity search can be optimized with the APU hardware and software.
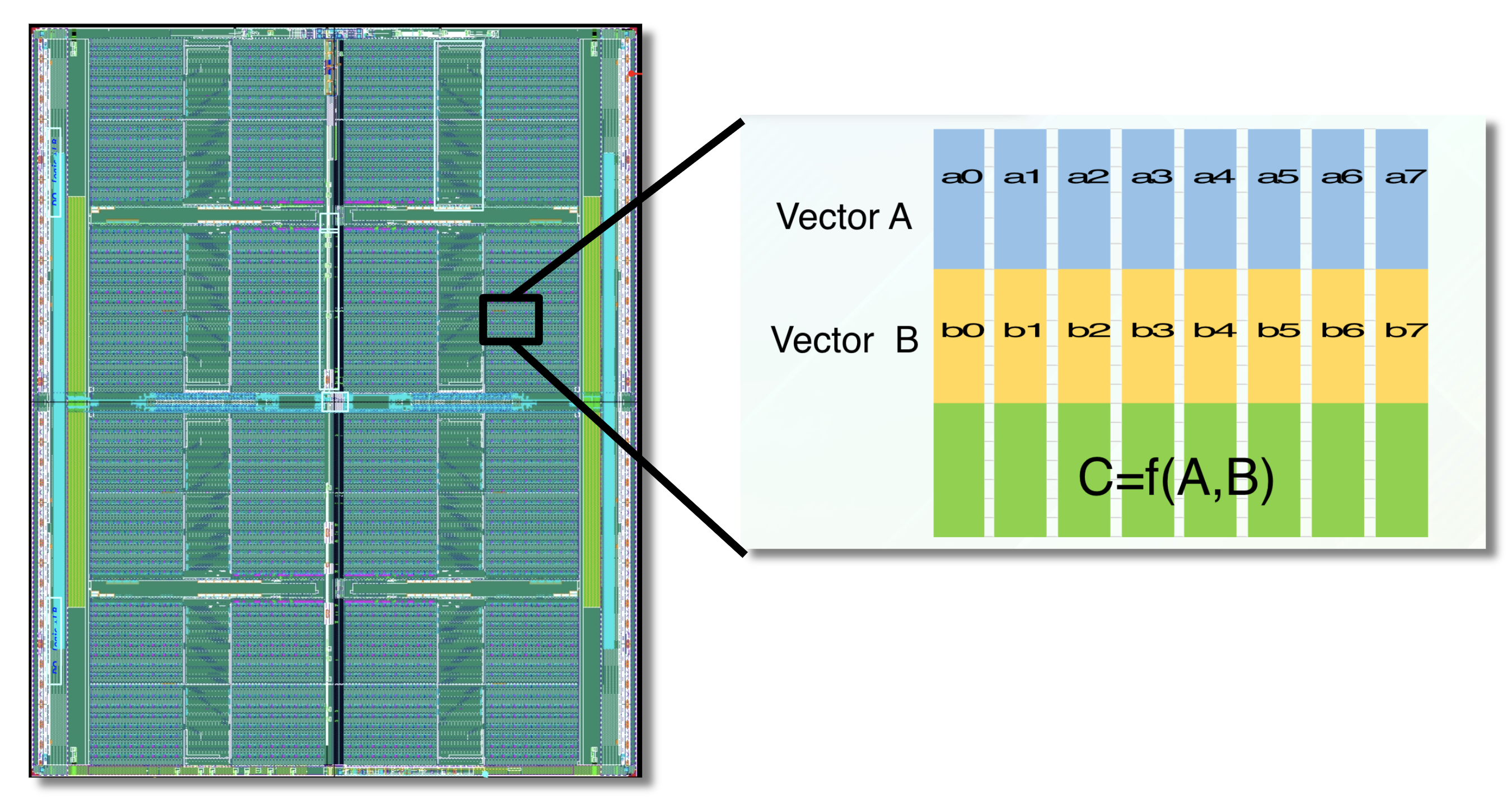
Bit-logic is interleaved throughout the chip memory, computing on the data “in-place”.
A picture of the chip is shown above. If you think it looks a lot like standard computer memory, you are right! GSI has leveraged its twenty years of experience creating high performance DRAM and SRAM in designing the APU.
The key difference is the bit-logic. There are 2 million of these modules interleaved throughout the chip and each can be programmed to compute simple functions on the data “in-memory.” That’s a massive number of simultaneous computations! And by computing on the data where it lives, the APU can eliminate many of the memory transfer bottlenecks that exist in most standard computer architectures.
A pure embedded approach might bake an algorithm directly into the silicon. The APU takes a different approach. The APU bit-logic can be programmed. This means it can accelerate the computation of several different kinds of distance functions. For example, in addition to hamming distance, the bit-logic can be programmed for the Tanimoto distance, a popular distance function in molecule search. In addition to bit-vector based distances, the APU can be programmed to compute the standard floating point-based distances as well, such as cosine and Euclidean distance.
The APU supports and accelerates many ANN techniques, including ones that are core to the popular FAISS open source similarity search library. We support Locality Sensitive Hashing (LSH) and Product Quantization-based algorithms, and we are actively investigating other ANN methods.
We’ve performed some preliminary benchmarks on the SIFT1M dataset. The graphic below shows how the APU can accelerate LSH-based hamming search (orange line). We’ve compared it to other popular FAISS algorithms.
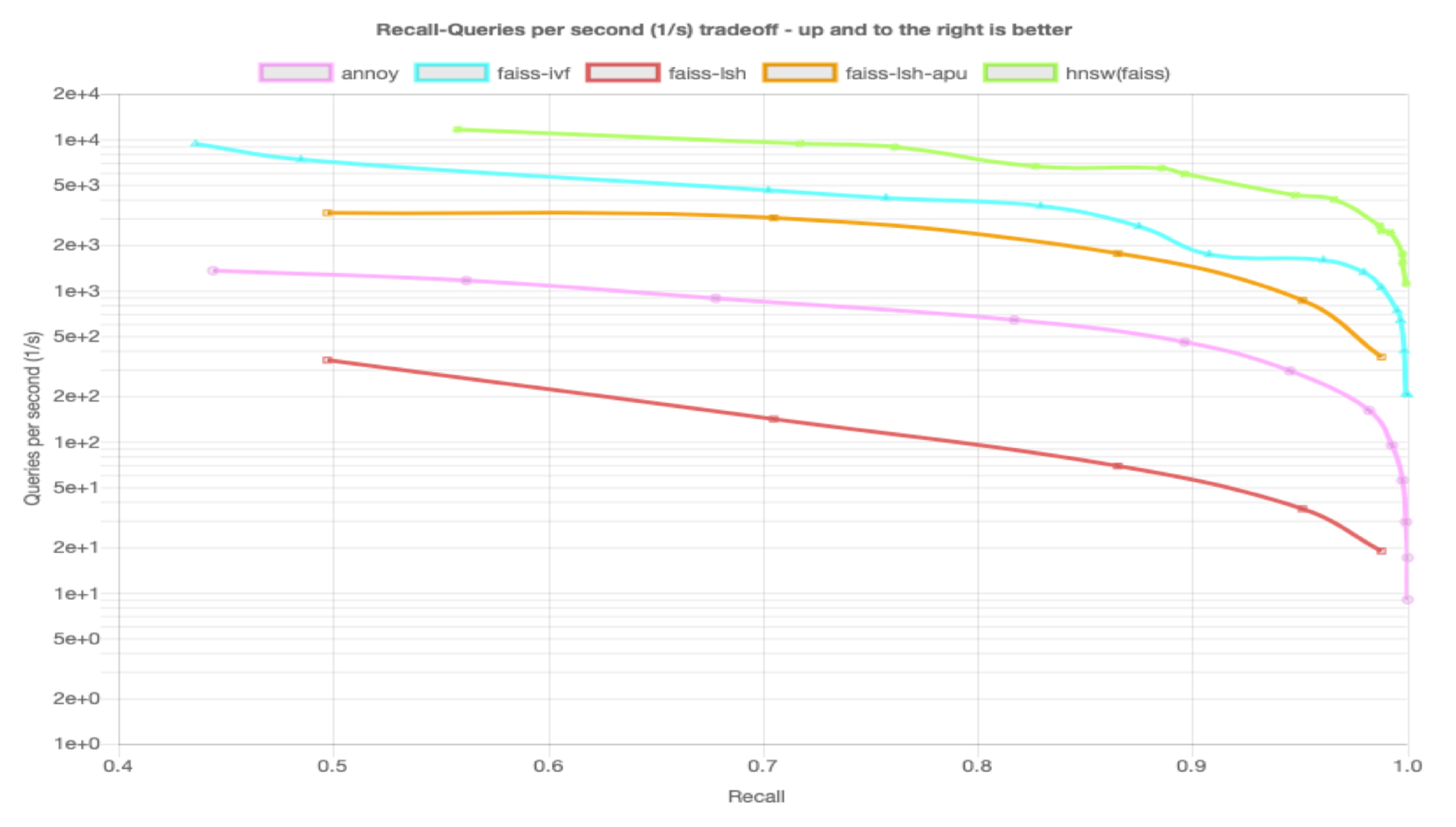
Comparing the APU LSH approximate nearest neighbor to other state-of-the-art ANN methods.
As you can see, we are competitive to other state-of-the-art ANN methods, including HNSW and IVF. But this is just the beginning, as we’ve only just started to scratch the surface accelerating ANN in the APU.
We are actively exploring other optimization tricks, including the following research topics:
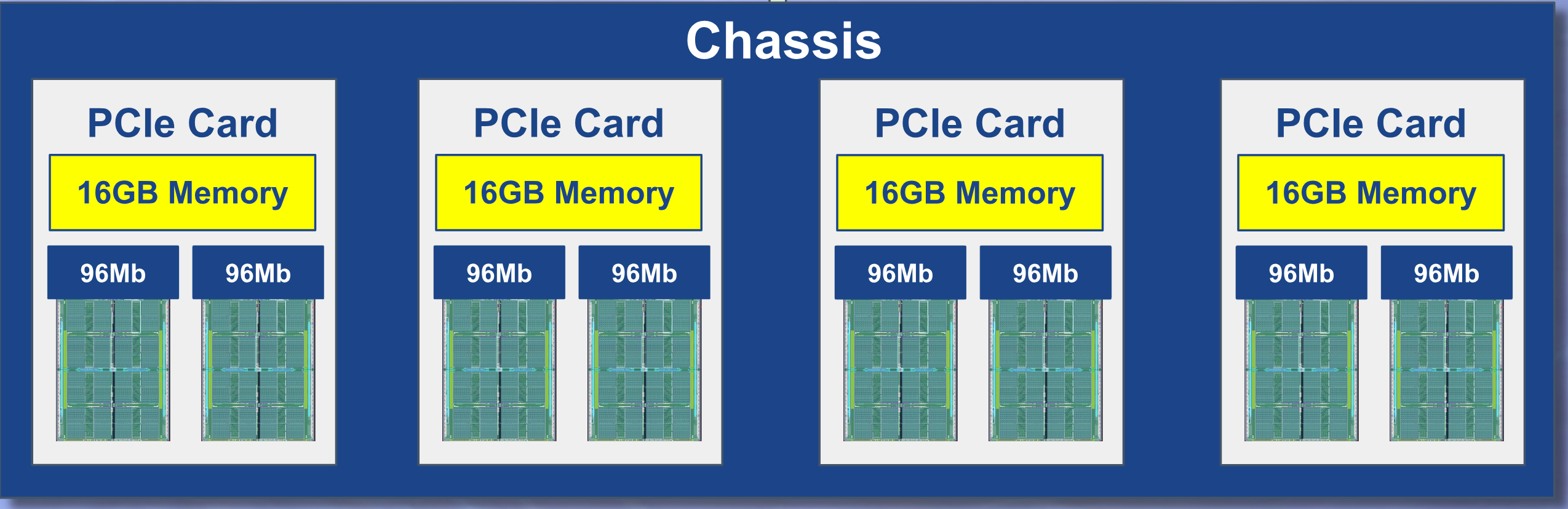
Four (4) APU boards fit into a 1U rack. That’s 8 APU chips working together accelerating very large scale similarity search.
The APU chip has 96 megabits of fast L1 cache. We have put two chips into 1 PCIe board, which has 16 gigabytes of main memory. So, one board is enough for many similarity search applications. For example, the Weizmann Institute uses 1 APU board to accelerate molecule search on a database of 16 million molecule fingerprints (fingerprint size = 1024 bits).
For even larger databases, we support clusters of multiple boards. A 1U rack system can house 4 tightly clustered boards. We also support multiple racks working in unison, as well as sourcing data from Network Attached Storage (NAS) via Remote Direct Memory Access (RDMA).
We are actively working with our partners and collaborators, integrating the APU system into their similarity search applications. For example, we have integrated the APU into the Biovia Pipeline Pilot, a popular application used in the cheminformatics community.
Check out our similarity search demo for visual search below.
The APU visual search demo application. In this demo we use ResNet-50 as the feature extractor. Floating point features are binarized down to 2048 bits, using FAISS-LSH.
The APU can accelerate similarity search in many kinds of applications, including large scale face recognition. The APU is also applicable to other domains, such as Natural Language Processing and cybersecurity. Watch for our upcoming blogs on these topics.
Can your application also benefit from accelerated similarity search? Let’s discuss the possibilities. For more information and a customized demo with your data, please reach out to us at [email protected].





















